Campioni della Community
-

CocceCore
Circolo degli Antichi7Punti149Messaggi -

Alzabuk
Circolo degli Antichi5Punti348Messaggi -

Landar
Circolo degli Antichi2Punti14.262Messaggi -

SNESferatu
Circolo degli Antichi2Punti1.887Messaggi



Contenuto popolare
Visualizzazione dei contenuti con la reputazione più alta il 12/10/2025 in Messaggi
-
3 puntiVaelthar (Barbaro delle Tempeste) Con lo sguardo fulmino @Alzabuk come se mi avesse offeso nel profondo. Ma non riesco a nascondere bene questo tipo di emozioni e dallo sguardo di ritorno di Alzabuk capisco che non ha preso per niente sul serio quel mio primo sguardo. Allora provo un'altra strada e sussurrando passo al vago Nessun innamoramento! Sai, vorrei sciogliere solo un po' la tensione, niente di più, capisci a che alludo? Sarò riuscito a fargliela bere? Spero per lui che, anche se non se l'è bevuta, sappia quando fermarsi! Per ora era una domanda "innocente", ma sa benissimo come posso reagire quando il suo punzecchiare supera il limite. E continuo a camminare aspettando con fervore l'inizio di questa battaglia. GdRoff Io lo vedo più come sotto, mi fa più similitudine con quanto detto anche a riguardo di scuola di polizia 😁3 punti
-
2 puntiIl bello è che Ana potrebbe intuire che la suora ha qualcosa di malevolo, ma ha deciso completamente di ignorare il problema pensando di avere avuto una sorta di allucinazioni. Inoltre, non è sicura che Darius sia davvero Darius, perché potrebbe essere stato ucciso e posseduto dal bestio (ed è stato anche marchiato, ma non lo sa ancora). Fate 2+2, se scopre che Darius ha cercato di uccidere la suora Ana potrebbe avere una grande confusione. È difficile non metagiocare, diventa un po' più facile quando interpreti un'idiota [benevolmente parlando].2 punti
-
2 puntiAlzabuk, stregone della luna e invocatore Molto bene, Fulminato: ho solo paura che sotto un determinato livello di tensione ...tu smetti di funzioni! eh eh! Gli batto una mano sulla spalla, come per fargli capire che ho comunque capito l'antifona: adesso pensiamo a come ...elettrizzare la serata, ok? Il barbaro mi lascia davanti allo scarico che dà in lavanderia. Il pertugio è stretto ma riesco, non senza fatica, a scendere fino in lavanderia. Una montagna di panni attutisce la caduta. L'atmosfera secca è l'ideale per asciugare in fretta. Ma qui sembra che il lavoro sia parecchio indietro. Non c'è più odore di sapone, ma solo di panni sporchi da tempo: odore di polvere e di metallo ossidato. Le tracce di muffa, di funghi, delle colonie microbiche della biancheria sozza sembrano sterilizzate dall'aridità dell'aria e dal caldo. Sbircio dalla porta semiaperta sul locale centrale: non c'è ancora nessuno. O almeno: non c'è nessuno a portata della mia scurovisione, del mio olfatto e del mio udito. Ricordo che nella cella dall'altra parte dello stanzone c'è il deposito di agenti chimici: che sciocchezza tenere cose altamente infiammabili in un deposito così secco e caldo! Invece mi pare che nella cella di fianco alla lavanderia ci siano delle bobine di filo spinato. Mentre attendo che i miei compari sopraggiungano dalla porta a sud, sguscio fuori e provo ad aprire una grata sopra la botola, con l'intento poi di castarci al suo posto una illusione di pavimento "pieno".2 punti
-
2 punti@Voignar @Landar @Pentolino @Rafghost2 Dopo aver consegnato la sua balestra all'halfling, la guardia (in realtà un semplice bracciante) resta col palmo della mano destra appoggiato alla porta e segue con lo sguardo gli scampati all'invasione che salgono la scala a pioli. Arrivati sulle mura, l'attenzione è catturata dal nuvolone di fumo nero che sale dall'ospedale da campo, che impedisce completamente di verificare come si stiano muovendo e riorganizzando le truppe nemiche. Quel che è certo è che l'attacco lampo non è riuscito: i cadaveri di 4 orchi sono stesi a terra. I due inseguitori superstiti sono tornati indietro. Il kuckizzero si avvede dell'arrivo dei superstiti: Avete fatto una bella corsa! Non sono in molti quelli che possono dire di essere sfuggiti a piedi da una torma orchesca, complimenti. E dire che quando siete arrivati qui, eravate più morti che vivi! Poi vede spuntare dalla botola anche il capino di Mercurio. Ah, mezzuomo! Ti avevo perso di vista, ma voi piedilesti, evidentemente, avete la pellaccia dura. Ben fatto! E ti devo le mie scuse: non avrei mai scommesso un soldo sul fatto che uno della tua risma potesse essere d'aiuto in campo aperto poi, rivolto al ragazzo che è con lui sulle mura (ancora un adolescente con la mascella poco sviluppata, poco più di un bambino, ma con un torace e le spalle già larghe): Zev, mio caro ragazzo, tu hai una vista migliore della mia. Mi sembra che i nostri amici piromani si stiano riorganizzando. Vedi nulla? Meccaniche (Schede) Mercurio equipaggiamento completo + balestra (in mano) e 4 quadrelli (nell'altra mano), 16/18 HP,. Amirkhan - vesti da saltimbanco, 1 balestra (in mano), 1 borsa del guaritore a tracolla, 1 acqua santa, 1 simbolo sacro nelle tasche delle brache, 12 quadrelli, 6/17 HP. SLOT DI 1°liv terminati. Tarik - (2 livelli di affaticamento = svantaggio alle prove di caratteristica e velocità dimezzata) - vesti da saltimbanco, lancia (in mano), balestra (in mano), 1 kit da erborista, 1 fiala di acqua santa, 12 quadrelli (nelle tasche delle brache). 12/20 HP. Zev - equipaggiamento completo, full HP. Mappa Il terrazzo è difeso da merlature alte tra i 80cm e 160cm, larghe regolarmente 1,5m. Offrono quindi copertura totale, 3/4 o metà copertura a seconda del punto di osservazione dell'attaccante e della posizione del bersaglio. La superficie è 7x4m. Le merlature sono sia a ovest, sul campo di battaglia, che a sud, sul fiume, che a est, sul torrente. A nord una parete costituisce il lato sud della torre centrale, soprastante il portone e contenente la macchina per il ponte levatoio sul torrente a est. C'è una scala a pioli appogguata a questa parete, per raggiungere la terrazza superiore, e una feritoia che offre la vista al passaggio sottostante. Tutti Completiamo il party con un nuovo membro e direi che siamo a posto così 😄 Zev @Rafghost2 Non vedi orchi.2 punti
-
Beh Iskra potrebbe accendere una miccia se c'è occasione però eviterei di causare esplosioni nei locali bassi..hai visto mai cedesse qualche pilastro portante? ahahaha Senza causare esplosioni cmq, la Druida potrebbe castare Nube di Nebbia, ha un raggio di 6 mt. Tutti gli altri potrebbero nascondersi in attesa entro la nube, magari proprio vicino al bordo e quando sentiamo l'ingresso di eventuali invasori si esce quel tanto che basta per sferrare un attacco.2 punti
-
@Alzabuk Ho risposto ancora prima di aver letto tutte le risposte attentamente 😆 Direi che la mia idea di metterti in un secchio può farti capire quanto da un lato ti voglio bene e ti voglio proteggere, ma dall'altro voglio tenerti lontano da eventuali idiozie o pensieri imprevedibili che può fare/avere. Quindi finché è preparazione ti aiuto anche, ma se quando entrano non sei al sicuro stai tranquillo che i nemici sarebbero l'ultimo dei tuoi problemi 😘 Per ora mi sento un po' mamma orsa nei tuoi confronti, poi il mio atteggiamento potrebbe cambiare in base alle tue azioni2 punti
-
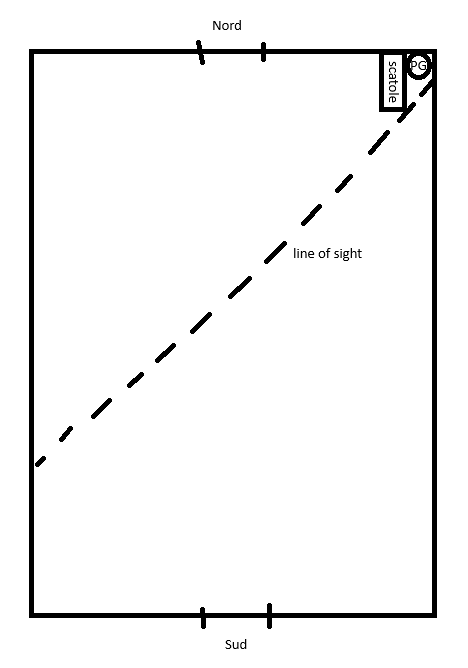
Io devo dire che mi ero immaginato le mura, le colonne ed il soffitto fatto interamente di pietre al grezzo tendenzialmente quadrate o rettangolari a file sfalsate per rendere il tutto più robusto. Invece, il pavimento me lo sono immaginato un po' come la cantina di mio nonno😅 tre cisterne per lato con le canalette usate per riempirle che partono dal collegamento a Nord e, seguendo i muri laterali, vanno a congiungersi alle rispettive cisterne. Un lastricato centrale dall'entrata sino quasi al collegamento a Nord ed il resto di terra battuta mista a ciottoloni (sassi tondi delle dimensioni di circa 15/20 cm di diametro) in modo che eventuali perdite venissero assorbite dalla terra e i ciottoloni permettessero di camminarci senza sprofondare nel fango che si sarebbe generato altrimenti o scivolare se invece fosse stato tutto di pietra, con il lastricato centrale che, essendo separato e lontano dalle canalette, serve da "terra ferma" per ispezioni veloci e facilità di spostamento di carriole o altro oggetti muniti di ruote. Diciamo solo che mio nonno adorava il vino e aveva diverse botti in questa cantina, ma non sempre quando andava a spillarlo era sobrio e il pavimento fatto così ha aiutato molto sia nell'evitare che scivolasse ma anche che non si versasse altro vino quando ne aveva avuto abbastanza. Non lo considero terreno difficile ma neanche facile, soprattutto se è la prima volta che ci si mette piede. @Steven Art 74 l'accatastamento di un 4/5 scatole in uno degli angoli a Nord quanto tempo mi richiederebbe? Più o meno un "muro temporaneo" alto 2m, largo 2m, profondo 1m? ti lascio un disegno molto approssimativo per farti capire. La mia intenzione sarebbe quella di nascondermici dietro ed avere quella copertura tale da far si che non mi vedano finché non avanzano un po' o vengono a vedere da vicino (oppure fanno saltare le scatole che è sempre un opzione). Un'idea molto semplice che da un lato non permette ne a me ne ai nemici di vederci direttamente, ma al contempo permette a me di vedere i miei alleati e quindi concordare un segnale per uscire allo scoperto e trovarmeli a tiro di alabarda in un tempo minore rispetto a percorrere tutta la cantina da parte a parte in piena vista. Alzabuk lo possiamo nascondere dentro uno dei secchi che stanno sopra le cisterne, tanto penso ci entri a pennello 🤣 Eriol, come diceva, potrebbe stare al centro dietro ad una delle colonne centrali in modo da essere a metà tra la prima linea e la retrovia. La nostra druida devo dire che è un po' difficile da nascondere, a meno che non diamo fuoco a tutto in modo preventivo, quindi forse potrebbe fare da esca col paladino Raven che sta nascosto nelle vicinanze pronto a fermare qualcosa tentativo di avvicinamento dei nemici a lei. Sono idee buttate lì di un sabato tarda notte, quindi molto probabilmente migliorabili e/o con buchi grossi, come quelli lasciati dai cannoni di un galeone, nella strategia.
 2 punti
2 punti -
1 puntoKarandrak Attenta Angrboda. Vogliono concentrarsi su di te. Credo abbia fatto incaz.zare il capo. Dico con un sorriso alla nostra ranger. Il suo è stato un bel colpo, speriamo solo possa sopravvivere alle conseguenze. Mentre Occhiotorto continua a mordere, in maniera ormai praticamente automatica, infondo le mie mani di energie curative, posandole poi sull' unico alleato abbastanza vicino a me, Frug. Le sue ferite iniziano a chiudersi a vista d' occhio. A dire il vero più che un' imposizione è un' energica pacca, quasi un ceffone sulla sua schiena, per quanto l' impatto sia limitato dal mio fisico gracile. Muoviti Frug, non restare lì impalato! Master Healing Devotion su Frug per dargli fast healing 1 per 10 round e occhiotorto continua a mordere.1 punto
-
Ho seguito (da completo profano) affascinato questi e altri test, ma mi pare che gli LLM siano arrivati al punto che non possono essere definiti AI: un elaboratore di testo solo "verosimile", sganciato infatti dal dato reale (da cui la frequenza di wrong answers), trovo sia meno intelligente di, che ne so, un navigatore che ha connessione con la realtà. Provocazione a sentimento: probabilmente un GoogleMaps adeguatamente istruito sarebbe più capace di farmi da master in un dungeon crawl. Sperimentare con la tecnologia del metaRL mi sembra in definitiva un miglior investimento del proprio tempo, invece che continuare a farci menare per il naso da chi ci vuole vendere come AI i propri LLM hallicinating-by-design. Senza pensare a quanto potrebbe costare in termini energetici una sessione di gioco di 3 ore con un elaboratore di testo probabilistico.1 punto
-
1 puntoAngrboda si defila dalla mischia e scaglia la sua lancia contro il capitano dei rettili. L'arma si conficca a fondo nella sua carne facendolo urlare dal dolore. La ferita alla spalla non è fatale ma comunque molto grave. La lancia lo ha passato da parte a parte e perde molto sangue. [Draconico] Concentriamoci su di lei! Ordina al compagno che ha vicino. I due le si avvicinano scagliando giavellotti e un proiettile la colpisce di striscio alla coscia procurandole un taglio superficiale. Intorno a Ghorza compare un area di pura oscurità. I rettili al loro interno iniziano a fuggire in tutte le direzioni e uno viene ferito da Frug e Occhiotorto ma entrambi i colpi sono frettolosi e poco efficaci. Karandrak bersaglia l'altro rettile in fuga. Il raggio gelido colpisce il bersaglio alla schiena strappandogli un sibilo di dolore. Il nemico è allo stremo e gli si legge sul muso che fa fatica anche solo a stare in piedi. Occhiotorto si ritrova circondato ma la sua pelle dura lo protegge dai colpi che si abbattono su di lui. Il duello di Nahaz e il lucertolide continua in uno stallo. Frug rimane impalato ad analizzare lo scontro. Azioni Angrboda movimento in T12, causa AdO da parte di R12 con randello 1+2+1(aura)= 4 mancato, lancio su comandante 20+5= 25 minaccia di critico 12+5= 17 colpito, critico confermato 1d8(2)+2= 4*3= 12 danni Nahaz attacca W10 con lancia 4+7= 11 mancato Ghorza Incantare sulla difensiva per Nessuna Luce, Concentrazione CD 15 18+2= 20 successo Karandrak raggio a contatto 13+1= 14 colpito 1d3(2)= 2+8 precedenti = 10 danni Occhiotorto attacca R12 con morso 20+3= 23 colpito, minaccia 11+3= 14 mancato non confermata 1d6(2)+1= 3+6precedenti= 9danni Comandante movimento in S15 con estrazione giavellotto e lancia su Angrboda 14+2= 16 colpito 1d6(3)-1= 2+2precedenti= 4 danni K10 movimento in J13, provoca AdO da parte di Ghorza pugno 4+3-4= 3 mancato, altro movimento in J16 M11 Movimento in P10, provoca AdO da parte di Frug pugnale 18+0= 18 colpito 1d4= 1, provoca AdO da parte di Occhiotorto lancia lunga 16+3= 19 colpito 1d8+1= 3+1 precedenti= 4 danni, secondo movimento in Q10 per uscire da Nessuna luce R12 movimento in Q12 e attacca Occhiotorto con randello 1+2+2(fianchi)+1(aura)= 6 mancato O14 movimento in R14 con estrazione giavellotto e lancia su Angrboda 7+1= 8 mancato W10 attacca Nahaz con randello 6+2+1(aura)= 9 mancato Frug non fa nulla Legenda: Angrboda (Verde) - 4/10 Ferite - Disarmata <-- Tuo turno, postate tutti Nahaz (Blu chiaro) - 7/14 Ferite Ghorza (Giallo) - 3/10 Ferite - Nessuna luce, Prona Karandrak (Viola) Occhiotorto (Rosa) Comandante nemico (Grigio) - 12 ferite [-6 FOR] Maestro di Tattica, Motivare Attacco Nemici (Nero) Frug (Blu) - 6/8 Ferite Tutta la 4mappa è da considerarsi terreno impervio perché state combattendo nel fango. No corsa o carica, il movimento costa doppio, no passetto di 1,5m.
 1 punto
1 punto -
1 puntoConcentrazione è praticamente obbligatoria per i caster in 3.5, di solito si alza dall' inizio ma fidati, è un' ottimo investimento.1 punto
-
eh si: il movimento su mappa è un benchmark in cui tutti i moderni LLM vanno male. Per usare le parole di Gemini stesso (che lo spiega benissimo): <<Yes, LLMs have problems with maps and mazes because they struggle with long-term path-planning, spatial reasoning, and avoiding context inconsistency hallucinations. While they can handle simple scenarios, complex or large maps often lead to failures, such as getting stuck in loops, and their performance degrades significantly as complexity increases. Current research is exploring new approaches to improve LLM navigation, such as multimodal models and methods that transform spatial information into more structured formats. Key challenges for LLMs with maps and mazes Lack of robust spatial reasoning: LLMs are trained on text and do not have an innate understanding of physical space, making it difficult to perform tasks like accurate pathfinding or spatial planning. Context inconsistency and hallucination: For long-term problems like a complex maze, LLMs can lose track of their "location" or the overall goal, leading to inconsistent and incorrect outputs, or "hallucinating" a path that doesn't exist. Memory and attention limitations: The length and complexity of a map can exceed the model's effective context window, causing it to forget previous steps or details necessary to solve the maze. Sensitivity to representation: How the map is presented to the LLM (e.g., text-based coordinates vs. a visual image) significantly impacts performance, and text-only representations can be particularly challenging. Inability to self-correct: Without explicit feedback mechanisms, an LLM will often confidently generate a wrong answer and persist in a flawed path, sometimes by looping endlessly. How researchers are trying to solve this Multimodal models: Using both text and images to provide the LLM with a richer understanding of the spatial environment. Spatial-to-Relational Transformation: Converting the spatial problem into a sequence of "entity-relation" chains, which leverages the LLM's strength in handling sequential data. Q-learning-based algorithms: Guiding the LLM's path-planning with a reinforcement learning approach that helps correct hallucinations and find the optimal path. Benchmark development: Creating structured tests, like MazeEval, to more accurately evaluate and understand the specific shortcomings of LLMs in spatial navigation tasks. >> EDIT: aggiungo inoltre che, a mio avviso, gli LLM sono una strada per l'AGI ma non la più promettente. Una strada diversa di cui imho sentiremo parlare in futuro è il Meta-Reinforcement Leraning. Riporto una conversazione tra me e Gemini: <<Ciao Gemini, in passato stanford ha fatto un ricerca. Un agente addestrato con RL deve imparare a uscire da labirinti. Tra le azioni dell'agente c'era quella di leggere il contenuto di una stanza. Dove leggere vuole dire 'visualizzare l'immagine raster'. Ebbene se le parole che leggeva lo aiutavano a trovare la via d'uscita l'agente imparava a leggere senza essere mai stato addestrato specificamente per questo. Puoi darmi più informazioni? Ho solo vaghi, confusi ricordi su questa ricerca.>> <<Ciao! Certamente, ricordo questa affascinante ricerca. Il tuo ricordo, sebbene confuso, è estremamente accurato. Lo studio è un esempio notevole di come le reti neurali possano sviluppare competenze linguistiche emergenti se queste si rivelano essenziali per massimizzare la ricompensa, anche senza essere state esplicitamente addestrate al linguaggio. Ecco i dettagli su questo esperimento, che è spesso associato ai ricercatori di Stanford e al concetto di Meta-Reinforcement Learning (Meta-RL). 🧠 L'Emergenza del Linguaggio Negli Agenti RLLa ricerca che hai in mente si concentra su agenti addestrati tramite Reinforcement Learning (Apprendimento per Rinforzo) in un ambiente che richiede all'agente di leggere un'informazione per completare la sua missione. 1. L'Ambientazione e l'ObiettivoL'esperimento non si svolgeva in un labirinto generico, ma in un ambiente a griglia più complesso, spesso rappresentato come un complesso di uffici o un'area multi-stanza. Agente: Un’agente di Meta-RL (spesso un modello di memoria esterna come DREAM) con una rete neurale non addestrata alla lettura. Compito: L'agente doveva trovare un obiettivo specifico (ad esempio, una stanza contrassegnata da un colore o un oggetto specifico). Ricompensa: L'agente riceveva una ricompensa positiva solo quando raggiungeva l'obiettivo corretto. 2. La Mossa Cruciale: "Leggere il Contenuto"La caratteristica fondamentale era la presenza di un'azione a disposizione dell'agente: "osservare" o "leggere" un segnale o un'etichetta presente nell'ambiente. Il Segnale: In genere, l'ambiente era costruito in modo che la posizione dell'obiettivo venisse rivelata solo da un cartello o un segnale testuale (o visivo, come un colore) situato in una stanza informativa (la "stanza di lettura"). L'Input Visivo: Quando l'agente eseguiva l'azione di "leggere", l'input che riceveva la sua rete neurale era l'immagine rasterizzata (il testo visuale) di quel segnale. 3. Il Meccanismo di Apprendimento Senza SupervisioneL'agente non era mai stato addestrato a riconoscere le lettere o le parole (non aveva un modulo di Optical Character Recognition - OCR). Allora, perché ha imparato a leggere? Necessità Funzionale: Per risolvere il labirinto, l'agente doveva compiere una sequenza specifica di azioni: 1. Andare al segnale → 2. Leggere il segnale → 3. Ricordare l'informazione → 4. Andare alla stanza obiettivo. Massimizzazione della Ricompensa: Il Meta-RL, spinto a massimizzare la ricompensa finale, ha scoperto che l'azione di "leggere" innescava una sequenza di stati che portavano invariabilmente alla ricompensa. Associazione Profonda: La rete neurale dell'agente ha associato le specifiche forme dei pixel che componevano le parole (es. la parola "ROSSO") a un vettore di stato interno (la sua "memoria") che poi portava a movimenti coerenti con il target corretto (la stanza rossa). In altre parole, la rete ha creato un proprio "vocabolario" interno, dove una specifica configurazione visiva di pixel significava "vai a nord-est", senza mai capire il significato umano della parola. Questo ha dimostrato che le abilità linguistiche non devono essere necessariamente apprese con un addestramento supervisionato, ma possono emergere come strategie di alto livello in ambienti complessi di Apprendimento per Rinforzo se si rivelano funzionalmente necessarie per raggiungere un obiettivo. È un passo fondamentale verso agenti che apprendono in modo più olistico, come gli esseri umani. 💡 [....]>>1 punto
-
1 puntoGhorza , Cleric , grey orc female Il sapore del sangue del lucertoloide mi invade la bocca e per un attimo la mia fame si placa e in quel momento un altro nemico mi colpisce trapassandomi le carni fino a farmi crollare a terra in una pozza di sangue... Ah il freddo abbraccio del fango e della morte quali sublime e straziante sensazione pervade il mio corpo mentre la vita mi abbandona... ma la mia ora ancora non è giunta e una luce bianca mi toglie dalle mie care tenebre... confusa riapro gli occhi ma è solo questione di secondo ed il clamore della battaglia mi risveglia a terra guardo Flug chino su di me e i nemici che dall'alto mi guardano ghignando... Ringhio con tutta me stessa mentre con una mano traccio degli strani simboli nell'aria... @ DM Lancio l'incantesimo di livello zero Nessuna luce per fare comparire una zona di oscurità di raggio sei metri centrata sulla mia persona , la scurovisione funzione la vista normale no . vedi tu se subisco o meno un attacco di opportunità.1 punto
-
1 puntoDieter Approfittando della sua vicinanza al circolo dei cospiratori e della libertà di movimento che gli derivava dal fatto di non avere ostacoli lungo il breve percorso, Dieter balzò fuori dal suo nascondiglio, un ringhio urlato sulle labbra, mentre mulinava la spada e si scagliava contro quei mostri travestiti da ricchi e pasciuti agnelli.1 punto
-
1 puntoShamàsh - Eoldred Leah La breve esplorazione effettuata in compagnia di Vysara e Seraphina non ha portato quasi ad alcuna conclusione. L'evento che ha trasformato la Luna in questa inquietante sua nuova forma non ha trovato alcuna risposta. Sono piuttosto preoccupato, non ho idea se in questo mondo sia accaduto già altre volte in passato, quel che è certo è che non può essere una coincidenza considerando le reminiscenze che ultimamente stanno riempiendo i miei sogni. La luce della Luna si posa sul fogliame, i rami degli alberi sembrano come sanguinare. I miei occhi sono due piccoli fari nell'oscurità della foresta mentre la mia armatura riflette i rossi raggi lunari che filtrano tra le fronde, sembra quasi io abbia affrontato chissà quale battaglia. Percepisco dolore e tristezza nell'aria, paura e rabbia. Da un punto non ben definito di fronte a noi giungono urla di combattimento, forse ruggiti e sicuramente ululati. Vedo preoccupazione nello sguardo di Vysara e acceleriamo il passo. Improvvisamente la cupa foresta illuminata esclusivamente dalla rossa luce della Luna si apre, mostrando una piccola radura con al centro un'accogliente casetta preceduta da un giardino decisamente ben curato. La nostra destinazione. Il mio incedere è sicuro ma guardingo. Emergo dall’oscurità ammantato di argento e luce. Non siamo soli però, strani individui sono di fronte alla figlia di Vysara e a sua madre. Uno di loro, coperto di sangue e ferite sembra piuttosto minaccioso. Afferro lo scudo assicurato alla schiena ma non sguaino la spada, attendendo al limite un cenno della padrona di casa. La squillante voce della ragazzina però squarcia in due la tensione, riportando un fragile attimo di gioia. Le presentazioni seguono una breve spiegazione di quanto è accaduto, i tre estranei si sono quindi mostrati non solo utili ma anche coraggiosi. Faccio qualche passo in avanti dopo aver lanciato un breve sguardo verso Selyra. "Io sono Shamàsh, ma potete chiamarmi Eoldred se vi rimane più facile. E' un piacere anche per me, le circostanze mi sembrano invece ottime, chissà cosa sarebbe accaduto a questa bimba e sua nonna senza di voi." subito faccio qualche passo avanti verso il tiefling osservando le sue ferite "Lo scontro deve essere stato molto duro." superficialmente posso notare solo le pesanti artigliate o forse morsi, il guerriero però si regge anche il costato come se avesse qualche osso rotto. Non appena mi avvicino alle ferite di Zarath le mani iniziano ad illuminarsi di una luce giallo argentea, quella di una luminosa Luna crescente... di qualche ora fa. Al tocco le ferite iniziano a richiudersi e gli scricchiolii delle costole rimarcano che anche quelle stanno iniziando a ripararsi. "Non è forse ancora sufficiente ma se ne hai necessità posso fare di più. Voi altri avete bisogno di cure? Siete stati solo feriti o le creature che avete affrontato avevano artigli mefitici." L'espressione è serie ma è come se le mie labbra si piegassero in un caloroso sorriso quando finisco la domanda. "Linden? Avete smarrito la direzione? Comprendo che questa Luna possa disorientare." alzo lo sguardo al cielo con un po' di preoccupazione. Master uso 20 punti di imposizione delle mani su Zarath, se nessuno ha afflizioni particolari o è avvelenato allora ne uso 251 punto
-
1 puntoMercurio Senza aggiungere altro, trotterello dietro ai due guerrieri pronto a dare il mio contributo. Domanda al narratore Se ce ne sono ancora, prendo balestra e quadrelli o frecce se ce ne sono1 punto
-
Interessante. Vorrei condividere che ultimamente ho fatto molte prove con Gemini 2.5. Nel mio caso gli ho fatto fare il master ed io il giocatore. Con Gemini da cellulare, nella modalità live, si riesce a giocare avventure GDR divertentissime (in solitaria). Gli specifico l'ambientazione che voglio (giusto il nome, tipo alla Lovecraft, Sci-fi, piratesca) , qualche dettaglio sul personaggio che voglio interpretare e eventuale descrizione di uno o più PNG che mi facciano da compagni. A questo punto Gemini mi fa da narratore: si inventa la trama, impersona i PNG facendoli parlare , mi pone di fronte a delle scelte di trama e reagisce attivamente a qualsiasi bizzarria ruolistica mi passi per la mente, dando vita volendo ad una specie di narrazione condivisa. Discorso mappe Con Gemini PRO invece, mi sono dilettato ad addestrarlo per farmi da avversario nel vecchio gioco da tavolo D&D skirmish game. Con discreti risultati. Mi dice quali miniature vuole attivare, come le vuole muovere sul tabellone ecc...Difficile è stato fargli capire le mappe. Dalle mie prove, non è ancora abbastanza potente da capire le mappe a partire da loro immagini "raster" (JPG ecc..). Ho dovuto trasporre in Excel le caratteristiche delle mappe, specificando in ogni casella della griglia quali attributi vi fossero (es. muro, acqua, movimento difficile ecc...). Un lavoraccio. E comunque giocare un'intera lunga partita è ancora molto dura. Ogni tanto tende ad allucinare o comunque, dopo numerosi prompt di botta e risposta, perde i dettagli di quanto detto precedentemente, regole di gioco comprese... Comunque già quello che fanno attualmente queste IA mi risulta sbalorditivo e c'è da aspettarsi che migliorino sensibilmente in tempi brevi.1 punto
-
1 puntoAmirkhan "Bene." emetto un profondo sospiro come a recuperare le energie, sollevato anche dalla bella reazione del contadino. Gli lancio un ultimo sguardo di intesa prima di accennare un assenso con un cenno del capo verso Tarik. "Andiamo a vedere cosa sta succedendo, mi terrò fuori dalla gittata dei dardi nemici ma troverò il modo di darvi supporto."1 punto
-
1 puntoScusa pensavo di averlo scritto, quello verde tra le due colline con la montagna alle spalle1 punto
-
1 puntoAvevo visto il nome del PNG ma poi mi è passato di mente. Scusami, dal prossimo post correggo. Per quello che riguarda MasterX è solo stato aggiunto alla lista della panchina. Non mi pare giusto che superi gli altri giocatori in attesa e poi per la mia capacità di gestione quattro giocatori sono sufficienti.1 punto
-
#08 Soladain 21 Yarthmont 992, pomeriggio [sereno - fine primavera] @Vass e Grigory Vass e Grigory iniziarono a cercare fra i libri che erano alle spalle di Crackle Erano scritti in un linguaggio simile al Traladariano ma in una forma arcaica: erano per lo più libri di culto ma in uno erano riportate notizie sul Kartoeba, sotto forma di leggende espresse come poesie Il Kartoeba era descritto come il protettore buono delle profondità del tempio, per nulla violento e sempre mite. Nulla vi era scritto su come fermarlo poichè il Kartoeba era presentato come 'buono'1 punto
-
1 punto@Grimorio Non so. Intanto bisognerebbe chiarire che cosa intendiamo per “semplicità” in un gioco di ruolo, perché se non abbiamo un vocabolario comune rischiamo di parlare di due cose diverse. Detto questo: una parte della complessità che segnali in AD&D 2E deriva dal modo in cui furono scritti e impaginati i manuali nel 1989. È un problema di organizzazione editoriale, non tanto di regole. Va anche detto che in AD&D gli incantesimi erano estremamente caratterizzati per classe. “Dividere le acque”? Subito riconosci che è un incantesimo da chierico, e quasi nessun altro ci avrebbe avuto accesso. Questa distinzione netta contribuiva a dare identità alle classi. In 5e invece la maggior parte degli incantatori attinge dallo stesso calderone: maghi, chierici, stegoni, bardi ecc. condividono molti incantesimi, e questo a volte annacqua la specificità di ciascuna classe. Passando alla creazione del personaggio, è vero che in AD&D le caratteristiche hanno più valori collegati, non il semplice +X/-X della 5e. Però quei valori, una volta riportati sulla scheda, non cambiano praticamente mai: gli aumenti sono quasi inesistenti, quindi ciò che scrivi all’inizio resta valido per tutta la carriera del personaggio. In 5e invece i bonus si aggiornano regolarmente, ogni tot livelli. E qui aggiungo un altro elemento: il passaggio di livello. In AD&D era questione di cinque minuti: tiri i dadi vita, aggiorni i tiri salvezza, magari guadagni qualche nuovo incantesimo o potere ed è fatta. Nella 5e 2024, sfido chiunque a passare di livello in 5 minuti senza strumenti digitali. Ci sono sottoclassi, talenti, privilegi, nuovi incantesimi ecc.: il regolamento è più uniforme, ma il processo è tutt’altro che immediato. Guardiamo una scheda di un personaggio di 6°-7° livello: In 5e il giocatore è sommerso da opzioni: sottoclasse, background, capacità razziali, talenti, incantesimi, privilegi… Per un veterano può essere stimolante, ma per un novizio può diventare un blocco. Non a caso spesso i giocatori passano minuti interi a decidere che cosa fare. In AD&D invece le classi erano più rigide e avevano un ventaglio limitato di possibilità. Potevi fare meno cose, ma almeno la scelta era immediata e il gioco più fluido. Ecco perché secondo me bisogna distinguere: La 5e ha un regolamento più semplice e unificato, ma un gioco più complesso da gestire sul personaggio. AD&D 2E ha un regolamento più grezzo e dispersivo, ma al tavolo il giocatore ha meno cose da ricordare e gestire. In altre parole, la facilità di gioco non coincide sempre con la facilità del regolamento.1 punto










This leaderboard is set to Rome/GMT+02:00